腾讯的AI困局快讯
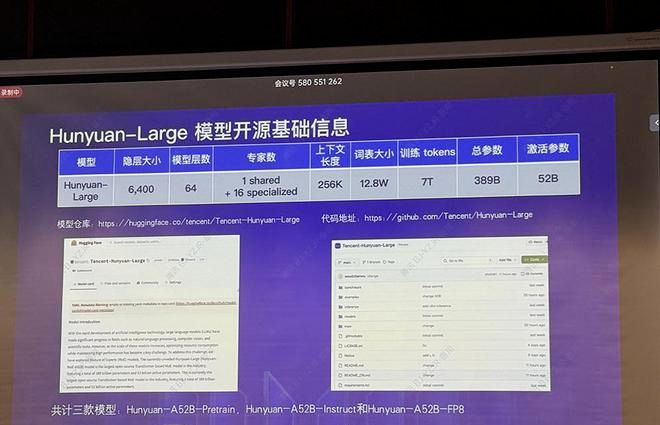
11 月 5 日,腾讯宣布开源 MoE 大语言模型混元 Large,腾讯称混元 Large 是业界参数规模最大、效果最好的开源 MoE 大语言模型,采用 7T 训练 tokens,总参数量 389B,激活参数量 52B,上下文长度高达 256K。

@科技新知原创
作者丨林书编辑丨蕨影
2024年已经逐渐步入了尾声,但国产大模型的内卷之战却还在继续着……
最近,腾讯终于有了新动作,在开源模型上卯足了劲。11 月 5 日,腾讯宣布开源 MoE 大语言模型混元 Large,腾讯称混元 Large 是业界参数规模最大、效果最好的开源 MoE 大语言模型,采用 7T 训练 tokens,总参数量 389B,激活参数量 52B,上下文长度高达 256K。
然而,从去年年初至今,在文本大模型的战场上,身为BAT三巨头之一的腾讯,却长久地处于被动的状态。
一个明显的表现是:在10月国内Web端AI助手的排行榜上,腾讯的AI产品元宝仅排在了第11位,月访问量不到200万,远不及百度的文心一言、与阿里的通义千问。
如今,在国内的AI应用上,要问起知名度最高的前三个,人们可能很难会想到腾讯的元宝。
问题来了:同样身为BAT三巨头之一,且有着微信这样一个超级入口,为何腾讯却在C端方面表现如此不堪?
一个重要的原因,恐怕并不是腾讯的元宝有多“差”,而是在于在众多国产大模型的AI产品中,元宝是一个十分四平八稳,平庸到毫无“特色”的存在。
而这样的平庸,对于腾讯这样的巨头而言,并不是一个及格的答卷。
及格边缘

基于腾讯混元大模型的的AI产品——元宝,目前在C端的体验究竟怎样?
在这里,我们以当前文本大模型最核心的几项能力,例如文本总结、撰写,深度推理等,将元宝与排名较前的一些大模型进行对比,或许就能从中得知其与目前一线模型的差距。
首先来看看文本总结。
在这里,我们先选取一篇关于低空经济的深度长文章,分别试着让元宝、Kimi,通义千问进行总结。
首先,我们试着让三个大模型,分别总结下,这篇文章的核心论点是什么。

从上到下的模型分别是:元宝、Kimi、通义千问。
可以看到,在三者的表现中,元宝最为简略,只草草地总结了文章的一些大致内容。
而相较之下,Kimi和通义千问的表现则详尽得多,不仅列出了数个要点,并且有条理、有逻辑地对文章的脉络进行了梳理,让用户有了一个大致的框架。
接下来,再看看文本撰写方面的表现。

在这里,我们的要求是:“用司马迁写《史记》的风格,叙述一下特朗普从2020年败选,到今年再次当选美国总统这段时间的经历,同时还要在叙述中,带有一些戏谑和讽刺的色彩。”
这样的要求,考验的就是模型在写作时的指令遵循能力。
先来看看元宝的表现。

虽然在写作风格上,确实比较接近《史记》,但是元宝并没有按我们的要求,从特朗普2020年败选的经历开始叙述,而是从他幼年的经历开始讲起,并且也没看出戏谑和讽刺的色彩。

之后是Kimi的表现,虽然在文风上,离《史记》还差了点,但是基本上已经做到了“从特朗普2020年败选的经历开始叙述”“带有一些戏谑和讽刺的色彩”这两点。

讲真,在这一轮比较中,三者表现最好的,就是通义千问了。从文风、叙述要点,以及情感色彩方面,都与我们的要求最接近。
之后,我们再看看三者在深度推理方面的表现。

这回我们的要求是:“联网搜索一下,目前各大咖啡品牌在县城等下沉市场的竞争态势,并分析这一态势背后的原因,之后从商业角度,给出一个独到的见解。”
这是一个复杂的分析型查询,需要结合实时数据,进行多步骤、多维度的分析。
在测试中,我们都开启了三个大模型的“深度搜索”功能。

由于答案太长,这里只截取最关键的“独到见解”部分。
首先来看元宝的表现。
平心而论,在元宝给出的见解中,只有“本地化”这一点,算是比较靠谱的,其他的看法,像什么“参与社区公益”“推广绿色消费理念”,都是些很外行,很不着调的回答。

之后是Kimi的回答。
跟元宝对比,可以明显感受到回答的深度、质量上了一个台阶。例如“数字营销”“优化供应链”这些见地,不仅一针见血,而且针对性很强,显然是考虑到了县城客流量低,对价格竞争更敏感的特点。

最后是通义的回答。
可以看到,在集合了之前Kimi针对性较强的特点上,通义的回答更为具体、细致,而不是看起来在“泛泛而谈”,其深度、针对性,与元宝相比,再次提升了一个等级。
通过以上测评,我们基本上可以看出:目前腾讯的元宝,在国内梯队中,仅仅只能算是“刚好及格”的那一批。
在文本总结、撰写这些日常任务上,其表现就已十分勉强,遇到一些需要复杂分析、推理的任务时,其水准就更不尽如人意。
组织“局限”

从当前国内大模型的概况来看,脱颖而出的玩家,往往有这么两类:
一类走的是市场路线,凭借其在多个业务线中积累的大量数据,将用户与内部场景进行深度整合,增强其在C端用户中的吸引力;这类的代表玩家,有百度、字节、阿里。
另一类则是以月之暗面、智谱清言为代表的,以硬核技术力作为核心锚点的企业,其主要靠模型过硬的实力吸引用户。例如月之暗面的Kimi,其模型在长文本的理解方面,在国内模型中就属于凤毛麟角。

从体量、实力上来说,腾讯完全有可能成为第一种玩家,甚至成为二者兼具的“双修”型选手,让人失望的是,作为一家拥有庞大社交生态、深厚技术积淀的巨头,腾讯却在这一领域“掉队”了。
究其根本,腾讯在语言模型领域的“拉胯”与其技术战略、组织架构不无关系。
首先,腾讯的组织结构问题是其在大模型领域失利的“罪魁祸首”之一。
从组织架构来看,腾讯采用了多部门参与的研发模式。据报道,腾讯的AI大模型研发涉及六个业务群(BG)的参与,其中TEG更侧重通用算法研发,而其他业务群则更关注行业应用。
这种策略有其优势(如贴近业务需求),但也带来了一些潜在的挑战(如协调成本较高)。

相较之下,BAT中的百度、阿里,在大模型方面的组织架构则集中得多。无论是百度智能云,还是阿里达摩院,都能在同一战略目标下集中算力资源,将模型与应用紧密协同。
腾讯的分离架构,在一定程度上导致了资源整合的困难,尤其是在GPU资源、算力需求等方面难以快速响应,从而影响了大模型的训练和应用速度。
说到底,这是因为腾讯长期以来专注于“社交”“娱乐”等业务的结构,决定了其组织形态更适合产品迭代而非技术突破,其技术研发更多服务于具体业务需求,而非系统性的基础研究投入。
虽然与腾讯相比,字节也同样是以娱乐内容起家的互联网巨头,但这其中的关键区别就在于:由于在短视频形成的内容导向策略,让字节跳动旗下的抖音、今日头条等产品需要时刻追踪用户喜好,快速迭代功能和内容,使得字节必须更注重算法、数据上的积累。

这一点从字节早期就开始构建的算法推荐引擎可见一斑——它不是在有了具体业务后才去开发技术,而是先有了技术积累,才催生出今日头条、抖音这样的产品。
而这与坐拥全国最大社交软件(微信、QQ)的腾讯,有着天然的差别。
产品掣肘

很多人质疑腾讯在大模型方面的滞后时,往往会想:既然腾讯背靠着QQ、微信这样的超级入口,那其为什么不将自身的元宝大模型整合进其中,通过流量效应取得优势?
关于这点,一个深层的原因,就在于微信和QQ等社交生态的崛起,靠的不是技术,而是运营策略和庞大的用户数。
靠着互联网时代“跑马圈地”的策略,腾讯已经稳坐了这个江山,对于腾讯而言,这是其最核心的资产,在此情况下,任何过于“新锐”的技术,都可能影响用户体验的改变,从而会被视为高风险操作。
尤其是当前大模型技术尚未完全成熟的情况下,各种幻觉、错误等问题,都会带来难以预料的负面影响。
更重要的是,社交场景中的对话往往涉及大量私密信息,如何在提供AI服务的同时,确保用户隐私安全,这是一个技术上和伦理上都极具挑战的问题。
而这也引出了一个有趣的悖论:在互联网时代,塑造各个巨头的优势因素,在AI时代,反而可能成为一种潜在的掣肘。
在当下大模型的竞争中,最重要的环节之一莫过于数据。
从这方面来看,腾讯的技术积累和商业模式与百度、阿里有着本质区别。百度长期深耕搜索引擎和知识图谱,积累了海量的结构化数据和自然语言处理能力;阿里则依托电商生态,拥有丰富的场景化数据和完整的产业链支持。

相比之下,腾讯虽然在社交领域占据优势,但其数据属性更偏向于即时通讯和娱乐,这在大模型发展的物质基础上就形成了先天差异。
更深层次来看,这样的差异,也反映了不同企业在面对技术变革时的路径依赖。腾讯的商业基因更偏向于连接与娱乐,而大模型技术的突破性应用,首先体现在知识服务和生产力工具领域。这种错位,使得腾讯在大模型竞争中不得不采取更为谨慎的策略。
这也是为什么,在垂直场景适配方面,例如在金融、医疗、教育等专业领域的技术突破上,腾讯明显落后于百度和阿里的系统性布局。

与百度、阿里建立构建统一的分布式计算框架(如飞桨、PAI),开发可复用的基础算法组件相比,腾讯的创新,更像是一种“自上而下”的模式:即为特定产品优化算法性能,解决局部场景的技术问题。
这样的技术差距,背后的根本原因在于腾讯的技术创新范式,与大模型这种需要持续深耕的底层技术存在结构性矛盾。
可以说,从早期的QQ到微信,再到现在的AI大模型,马化腾式的商业智慧,更多地体现在资本配置和生态搭建上,而非原始技术突破。
在互联网时代,腾讯通过投资大量初创公司和科技企业,以“买、买、买”的策略,极快的速度扩展了业务版图。在大模型和AI领域,腾讯大模型开发更多依赖开源技术和已有算法框架,但在核心技术积累上,并未能形成像百度的飞桨、阿里的M6这样的自研基础设施。
这助力腾讯构建了一个庞大、稳固的商业生态,但也形成了一种“宿命式”的依附。
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。
