MoE模型大火,源2.0-M32诠释“三个臭皮匠,顶个诸葛亮”!互联网+
实测万兴“天幕”:视频连贯性可圈可点,本土内容优势显著

文 | 智能相对论
作者 | 陈泊丞
近半年来,MoE混合专家大模型彻底是火了。
在海外,OpenAI的GPT-4、谷歌的Gemini、Mistral AI的Mistral、xAI的Grok-1等主流大模型都采用了MoE架构。而在国内,浪潮信息也刚刚发布了基于MoE架构的“源2.0-M32”开源大模型。
为什么MoE大模型备受瞩目,并逐步成为AI行业的共识?
知名科学杂志《Nature》在今年发表了一篇关于大模型未来发展之路的文章,《In Al, is bigger always better?》(人工智能,越大型越好?)。争议的出现,意味着AI的发展方向出现了分歧。
如今,“大”不再是模型的唯一追求,综合应用需要关注模型本身的计算效率和算力开销两大问题成为新的行业焦点。
浪潮信息人工智能首席科学家吴韶华在与「智能相对论」交流时也强调,事实上他们当前做的,是在模型能力持续提升的情况下,尽可能降低它的算力开销。因为今天大模型本身就是由两个主要因素来决定的,一个是模型能力,一个是算力开销。

浪潮信息人工智能首席科学家吴韶华
因此,MoE大模型的盛行,实际上对应的正是模型能力和算力开销两大问题的解决。这也是为什么众多大模型厂商如OpenAI、谷歌、Mistral AI、浪潮信息等陆续基于MoE架构升级自家大模型产品的原因。
MoE模型大火的背后,需要厘清三点认知
一、解题思路的转变:三个“臭皮匠”,顶个“诸葛亮”。
中国有句古语:术业有专攻,正是MoE模型的最直接的工作设计思路,即把任务分门别类,交由不同的“专家”进行解决。
如果说稠密(Dense)模型是个“全才”模型,旨在培养一个精通各个领域、能解决多个问题的“诸葛亮”,那么混合专家(MoE)模型则是个“专才”模式,侧重于培养多个“臭皮匠”(即“专家”),配合着以更专业、更高效的团队模式解决各种问题。
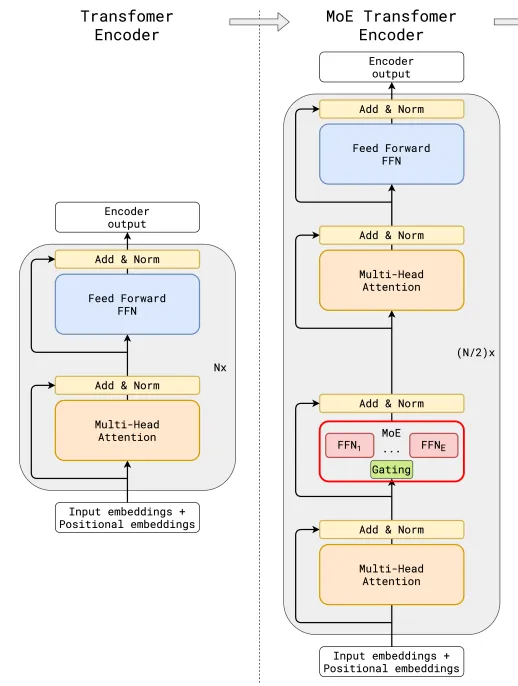
图片来源:《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》
由此便不难理解为什么MoE模型会如此火爆。因为,培养一个“诸葛亮”所需要消耗的资源、成本都太高了,甚至慢慢地超出了普通企业的承受范围。根据计算,训练一个5000亿参数规模的Dense模型,基础算力设施投入约10亿美金,无故障运行21个月,电费约5.3亿元——这是现阶段无法接受的算力投入。
那么,“三个臭皮匠”不仅能“顶个诸葛亮”,同时培养“三个臭皮匠”所需要的资源和成本可比培养“诸葛亮”可就相对简单多了。像源2.0-M32在处理逻辑、代码生成、知识等方面的能力是可以对标Llama3-700亿的,但其所需要但推理算力却低了一个量级,只有Llama3-700亿的十九分之一。
相当的智能水平,但算力投入却大幅减少,这也就意味着通过模算效率的提升,我们完全可以用更少的算力投入产出更智能的模型。这会是未来解决算力挑战的一个关键思路,MoE模型的大火,所带来的是一个AI行业解题思路的大转变。
二、算法层面的优化:三个“臭皮匠”的搭配和配合是一门艺术。
虽说“三个臭皮匠,顶个诸葛亮”,但是这“三个臭皮匠”如何选择、搭配以及配合处理任务,恰恰才是其“顶个诸葛亮”的根本。
更直观的对比,以古代作战为例,同样是一群人打架,为什么散兵游勇很难和正规军进行对抗、战斗?其根本在于正规军有专业的兵种搭配和配合,也就是“兵法”的辅助。放到AI领域,算法即“兵法”。
在MoE模型上,虽说核心思路是一致的,但是关于门控网络的位置、模型、专家数量、以及MoE与Transformer架构的具体结合方案,各家方案都不尽相同,由此将拉开各家MoE模型在应用上的差距。
比如,在算法层面,源2.0-M32就提出并采用了一种新型的算法结构:基于注意力机制的门控网络(Attention Router)。针对MoE模型核心的专家调度策略,这种新的算法结构更关注专家模型之间的协同性度量,有效解决传统门控网络下,选择两个或多个专家参与计算时关联性缺失的问题,使得专家之间协同处理数据的水平大为提升。
同时,源2.0-M32采用了源2.0-2B为基础模型设计,由此得以沿用并融合局部过滤增强的注意力机制(LFA, Localized Filtering-based Attention),通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,能够更好地学习到自然语言的局部和全局的语言特征,对于自然语言的关联语义理解更准确,进而提升了模型精度。
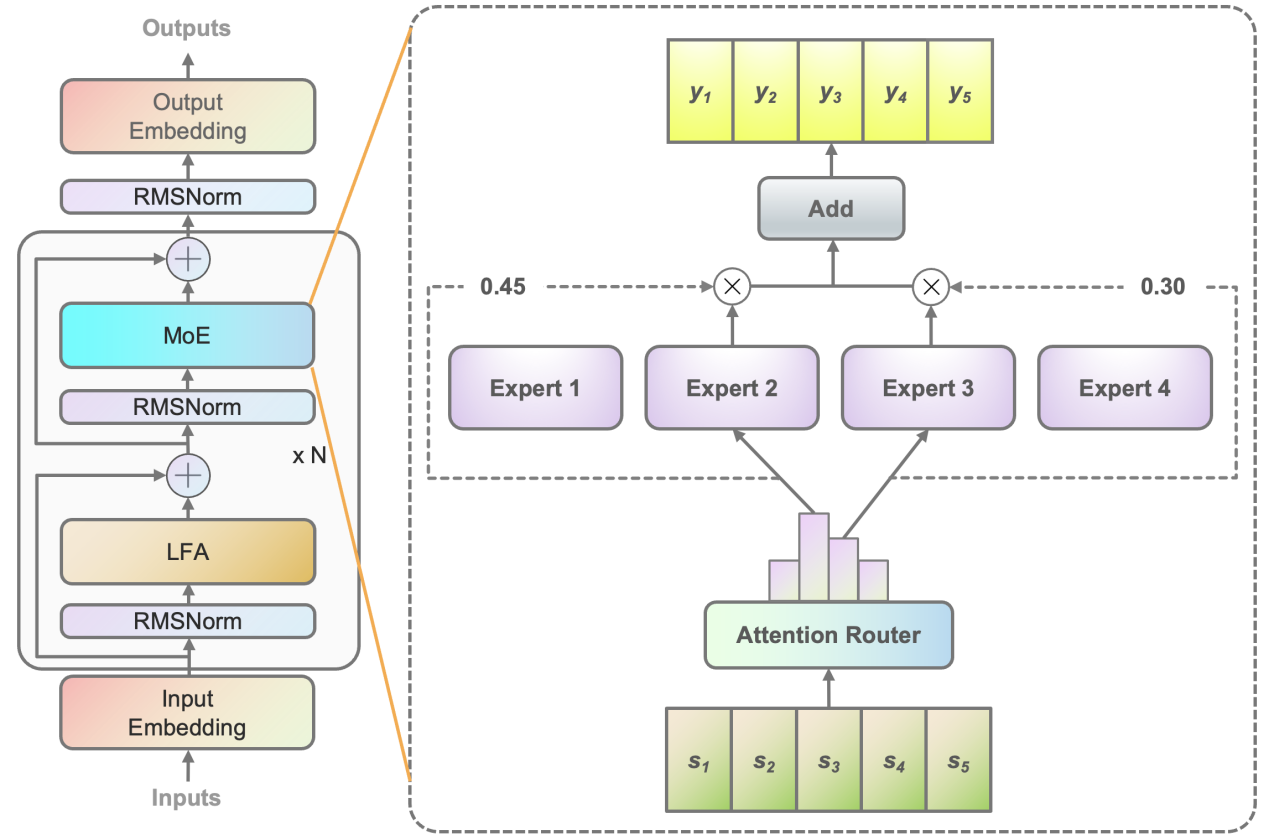
基于注意力机制的门控网络(Attention Router)
在MoE模型中,算法层面的优化将是模算效率提升的一个很好补充。简单来说,“三个臭皮匠”,能基于算法优化而发挥出更大的价值,在处理问题上得到更好的反馈。这或许也是接下来各家MoE模型进一步拉开差距的关键。
三、数据需求的延续:“诸葛亮”和“臭皮匠”都需要高质量的数据投喂。
这一点毋庸置疑,“诸葛亮”和“臭皮匠”同属于“人”,其成长的根本在于高质量知识的吸收。同样的,MoE模型和Dense模型也都同属于AI模型,都需要高质量的数据投喂,数据质量越高,对应产出的模型精度越高。
为什么源2.0-M32在代码生成、代码理解、代码推理、数学求解等方面有着出色的表现,其根本在于数据质量。源2.0-M32基于2万亿的token进行训练,覆盖万亿量级的代码、中英文书籍、百科、论文及合成数据。其中,大幅扩展代码数据占比至47.5%,从6类最流行的代码扩充至619类,并通过对代码中英文注释的翻译,将中文代码数据量增大至1800亿token。
总的来说,培养“臭皮匠”与培养“诸葛亮”所需要的资源并没有太多本质上的区别,只是培养的思路、方法有所优化,从而使得我们能用更少的资源、成本就培养出了一个能相当甚至是超过“诸葛亮”的“臭皮匠”智囊团。由此,MoE模型成了各大厂商争先布局的重要方向。
MoE模型普及的关键,仍需要解决最核心的算力问题
正如前面所说,MoE模型和Dense模型同属于AI,在发展需要上并没有太大的本质区别。因此,长期以来困扰AI发展的算力问题如算力太贵、算力供给不足、算力资源不平衡、算力利用率低等,还是MoE同样面对的,甚至是其走向大众市场的一个明显阻碍。
浪潮信息在发布源2.0-M32大模型时,吴韶华就提到,“这个模型我们在研发的初衷就是为了大幅提升基础模型的模算效率,在这里面有两个层面,一方面是提升它的精度,另一方面是降低同等精度水平下的算力开销。”
现如今,很多企业对MoE模型的重视大多聚焦模型能力,殊不知算力开销也是一个重要考量。若能花更少的算力,办更多的事情,那么对于MoE模型而言将是普及的关键。
目前,源2.0-M32大幅提升了模型算力效率,在实现与业界领先开源大模型性能相当的同时,显著降低了在模型训练、微调和推理所需的算力开销。
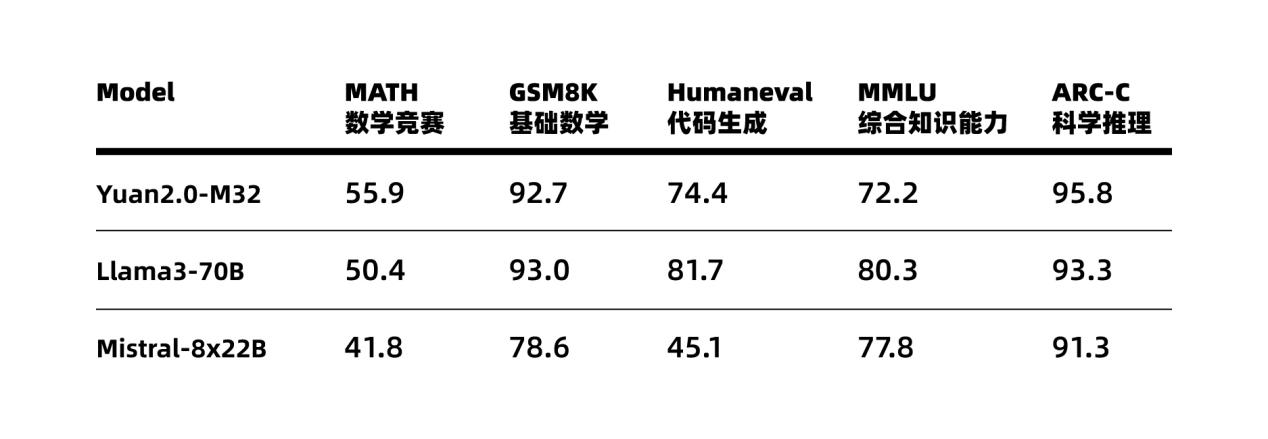
源2.0-M32业界主流评测任务表现
其中,在模型推理运行阶段,源2.0-M32处理每token所需算力仅为7.4Gflops,而LLaMA3-70B所需算力则为140Gflops。在模型微调训练阶段,同样是对1万条平均长度为1024 token的样本进行全量微调,源2.0-M32消耗算力约0.0026PD(PetaFLOPs/s-Day),而LLaMA3消耗算力约为0.05PD。
目前,源2.0-M32的激活参数为37亿,但是却取得了和700亿参数LLaMA3相当的性能水平,而所消耗算力仅为LLaMA3的1/19。如此大幅提升的模算效率,将为企业开发应用生成式AI提供一条“模型高性能、算力低门槛”的优质路径。
根据浪潮信息透露,源2.0-M32开源大模型配合企业大模型开发平台EPAI(Enterprise Platform of AI),将助力企业实现更快的技术迭代与高效的应用落地。也就是说,在技术层面,MoE模型将加速普及,而在应用层面,源2.0-M32所提升的模算效率,对模型能力和算力开销两大问题的解决将进一步加速生成式AI的普及应用,让更多企业都能享受到AI的时代红利。
写在最后
MoE模型并非人工智能技术前进的终点,更不是大模型发展的最终形态。但是,它的出现着实是改变了AI发展的路径,让AI落地有了更清晰的方向。
今天,大模型迫切地需要变得越来越大,但是单纯的变大并不能解决行业问题,大模型更应该想清楚如何变得越来越有用。“有用”是一个复杂的概念,既需要模型能力够强,也需要算力开销够小,让企业用得起、用得好。
浪潮信息所强调的模算效率就旨在解决这两大问题。事实上,从源2.0-M32的发布来看,模算效率的提升确实把MoE模型推向了一个更广泛的发展阶段,我们甚至能在此看到不同行业、不同企业都能用上、用好MoE模型的可能。
*本文图片均来源于网络
#智能相对论 Focusing on智能新产业新服务,这是智能的服务NO.264深度解读
此内容为【智能相对论】原创,
仅代表个人观点,未经授权,任何人不得以任何方式使用,包括转载、摘编、复制或建立镜像。
部分图片来自网络,且未核实版权归属,不作为商业用途,如有侵犯,请作者与我们联系。
•AI产业新媒体;
•澎湃新闻科技榜单月度top5;
•文章长期“霸占”钛媒体热门文章排行榜TOP10;
•著有《人工智能 十万个为什么》
•【重点关注领域】智能家电(含白电、黑电、智能手机、无人机等AIoT设备)、智能驾驶、AI+医疗、机器人、物联网、AI+金融、AI+教育、AR/VR、云计算、开发者以及背后的芯片、算法等。
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。