ChatGPT算崩了!GPGPU会成为算力危机的解药吗?金融
GPGPU通过 GPU 多条流水线的并行计算来实现大量计算,其已在通用GPU(即GPGPU)领域有所延申,尽管国内近两年在GPGPU领域已取得了很多的突破。
近日大火的聊天机器人程序ChatGPT,最终还是崩了!多位用户反映,其网站因为运算量过大,出现了无法回复的情况。
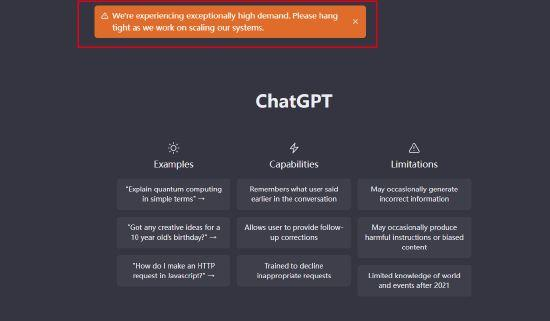
翻译:我们出现了远超预想的(运算)需求,请再坚持一下并等待我们将系统扩展。
事实上,ChatGPT出现崩溃只是算力紧张的一个缩影。近日随着百度、京东、腾讯等国内厂商宣布参与智能聊天机器人领域的竞争,未来类似ChatGPT这样的程序将越来越多。人工智能发展是大势所趋,全球市场对于算力的需求也将出现快速的增长。
GPU的“变种”在算力领域“挤走”CPU
提到算力,首先不得不说的就是CPU(Central Processing Unit,中央处理器)。1971年,英特尔生产的4004微处理器将运算器和控制器集成在一个芯片上,标志着CPU的诞生,这也是大规模机器运算的开始。后来从四位运算开始,每隔几年处理器的性能就会翻倍。
再之后,单纯的运算位数增加已不再满足复杂的运算需求,CPU逐渐向更多核心,更高并行度发展。典型的代表有英特尔的酷睿系列处理器和AMD的锐龙系列处理器。
CPU最大的特点是全能,作为中央处理器,其性能被平均分为多个模块,也因此CPU可以完成绝大多数指令下的任务,整体属于一款较为均衡的产品。
与此同时,由于电脑显示器的出现,传统的GPU(Graphics Processing Unit,图形处理器)也应运而生。显示器上的图形显示需要大量的重复运算(显示各种颜色,甚至三维图像),其对于算力的要求要远高于以处理指令为主的CPU。因此不同于CPU,GPU更强调了并行计算的方法,这也让GPU无论是算力还是运算速度,都要高于CPU。
随着显示器分辨率的不断提升,特别是多款大型游戏对于显示器分辨率的要求越来越高,GPU的运算性能也在飞速提升,而且提升速度快于CPU。
在这一方面,英伟达占据了GPU市场的头把交椅,不少人应该都有过为了某款热门游戏,而单独安装英伟达显卡的经历。
很长一段时间以来,CPU负责中央控制和各种运算,GPU负责少量处理和大量重复运算,两者相辅相成,各自担负起了对应的职能。
然而,有人看到了GPU相对于CPU高算力的优势,于是一种去掉了GPU图形处理部分内容,而仅保留了科学计算,AI训练、推理任务等通用计算类型的GPGPU(General-Purpose computing on Graphics Processing Units,通用图形处理器)诞生了。
GPGPU,可以说是特化版的运算芯片,GPGPU通过 GPU 多条流水线的并行计算来实现大量计算。超长流水线的设计以吞吐量的最大化为目标,在对大规模的数据流并行处理方面具有明显的优势。
如果说普通CPU的计算能力是小溪流,那么GPGPU的计算能力就是并行了注入多条河流的大江长河。在未来人工智能爆发的时代,其远优于CPU的运算性能,决定了这个GPU家族的“变种”在算力领域将“挤走”传统的CPU,大规模应用于算力市场中。
事实上,此前就有消息表示,ChatGPT已导入了至少1万个英伟达高端的GPGPU,不论此消息是否属实,ChatGPT至少很大概率使用了大量的GPGPU,并且好像已投入的部分还不够用,需要更多。一个高端GPGPU动辄数十上百万,这样看来,GPGPU的市场空间可能会非常大。
GPGPU生态:英伟达业内领先,国内生态初见雏形
事实上,一般的GPGPU确实具备了超快速的运算能力,然而,要想达到ChatGPT这种真正具备一定解决问题能力的成型AI系统,仍需要大量的开发工作,特别是需要海量的深度学习支持。AI才能面对并有效处理海量的问题。深度学习与GPU的图形处理有一些相通的地方,它需要大量的数据来“训练”模型。比如一个猫图识别AI,需要提供数以万计的猫图供其“学习”。而每一张猫图的学习又与其他猫图没有先后关系,每一张猫图,其实就相当于一次学习。
而如果缺少这些必要的开发学习支持,否则的话,GPGPU空有大量的运算能力,却不一定能够做出正确的运算。例如,前两天谷歌Bard的发布会中,就犯了事实性的错误,在一个“关于詹姆斯·韦伯太空望远镜(JWST),我可以告诉我9岁的孩子它有哪些新发现?”的问题中,Bard给出的一个答案是:太阳系外行星的第一张照片,是用JWST拍摄的。然而事实上,2004年,第一张系外行星照片是由欧洲南方天文台的甚大望远镜(VLT)拍摄的。
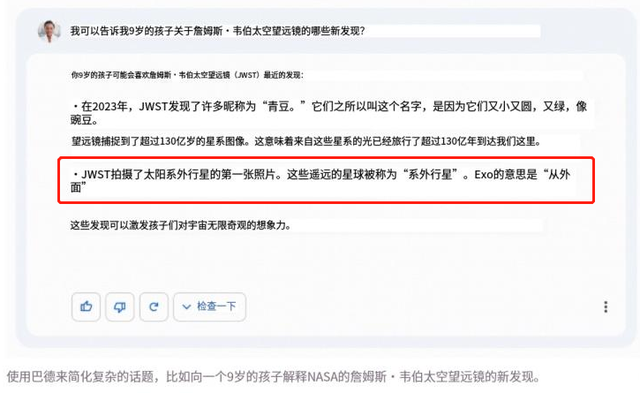
这种学习、运算与开发的过程,往往需要一个统一的开发架构,架构越优秀、越适配GPGPU。开发的效果也会越好。在这一领域,英伟达的优势比较明显,英伟达的CUDA(Compute Unified Device Architecture,统一计算架构)集成技术,占据了全球八成以上的GPGPU开发市场。通过这个技术,用户可利用英伟达的GPU进行图像处理之外的运算。由于绝大多数架构都是针对CPU进行编程的,更突显出了英伟达该架构的稀缺性。
不过,最近英伟达也遇到了越来越多的挑战,首先是一款新的架构PyTorch在AI开发领域大有后来居上的架势,由于其将支持更多GPU,相比于英伟达对GPU领域的垄断,受到了很多厂家的欢迎。而后续OpenAI(推出ChatGPT的公司)又发布了一款开源的GPU开发架构Triton。其虽然可以看作简化版的CUDA,但由于其采用较易编码的Python进行开发,且性能不输CUDA太多,最重要的是:其代码开源也意味着开发者享受着自由的环境,因此该开发架构也受到了很多开发者的欢迎。尽管目前Triton还只支持英伟达的GPGPU芯片,但其负责人员表示未来会支持更多厂商的芯片,做到真正的自由开发。
国内的GPGPU生态起步较晚,但近年来不断的投入,也在2022年有了一定的成绩。首先是在RISC-V(一种开源架构)中国峰会上,清华大学集成电路学院何虎副教授团队发布了基于RISC-V的开源GPGPU实现方案,名为“承影”(Ventus),同时还给出了映射方案、指令集和微架构的实现。
而上海交大在GPGPU架构领域,同样取得了不小的突破。2022年8月,上海交大团队正式对外发布了自研开源GPGPU平台“青花瓷”。“地缘政治所带来的不确定性在这几年有增无减,国产化的势在必行。利用开源及开源生态所创造的芯片,就有可能解决卡脖子的困境。发布这款芯片的团队主要成员梁教授表示。“通过十年的努力打造属于中国的GPGPU生态,做人人都用得起GPGPU,这是我们的愿景”。
国内GPGPU公司:有所突破,但仍任重道远
有了多样的生态,国内的一些GPGPU公司也在研发的道路上不懈努力,推出了一些有竞争力的产品。
2022年9月,壁仞科技首次展出了BR100系列GPGPU芯片,算力创下全球纪录。壁仞科技首款通用GPU芯片BR100,基于壁仞科技原创芯片架构研发,采用的是7nm先进制程工艺,可容纳770亿颗晶体管,16位浮点算力达到1000T(1T=1024G)以上、8位定点算力达到2000T以上。BR100芯片在国内率先采用Chiplet(先进封装)技术,使得中国的通用GPU芯片迈入“每秒千万亿次计算”新时代,最为振奋人心的是,这是第一次全球通用GPU算力纪录由中国企业制造。

随后,浪潮AI服务器成功搭载壁仞科技自研的高端通用GPU,在多项比拼中获评全球最佳性能,实现了国产芯片在国际AI赛场上的精彩亮相,取得了历史性的突破。
在A股上市公司当中,目前还没有以GPGPU为绝对主业的公司,但仍有与GPU业务有一定关系的上市公司,其中景嘉微经过多年的研发积累,公司在传统GPU设计及特定领域应用方面形成一定的技术、品牌等综合优势。公司在半年报中指出,其已在通用GPU(即GPGPU)领域有所延申,正持续研发并提供相关产品。
而以CPU为主要产品的海光信息,也已研发出了基于GPGPU的DPU(Data Processing Unit,中央处理器分散单元)产品,该产品其实是GPGPU的一种。其兼容“类 CUDA”环境,解决了产品推广过程中的软件生态兼容性问题。公司通过参与开源软件项目,并实现与 GPGPU 主流开发平台的兼容。
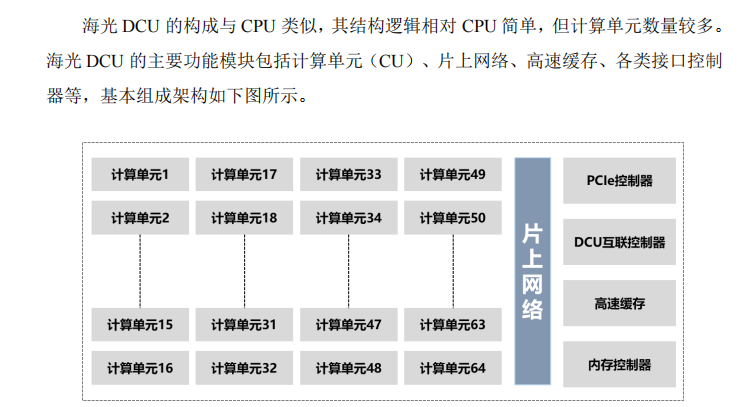
图片来源:海光信息招股说明书
值得注意的是,尽管这两家公司只是与GPGPU业务有一定关系,但两家公司近日双双大涨,其中2月9日景嘉微20cm涨停,海光信息也大涨超13%。市场或许也已意识到算力爆发背景下,GPGPU产业的投资机会。
除了上述公司外,登临科技、芯动力、沐曦半导体等公司,也正在GPGPU这条赛道上不断努力着。如果这些仍未上市的GPGPU公司选择上市,投资者也可以关注他们的动态,选择参与打新或二级市场的投资。
综合来看,尽管国内近两年在GPGPU领域已取得了很多的突破,但也要看到国外一些大型厂商已在该领域经历了数十年的发展,积累了丰富的经验和技术,并拥有着大量的上下游市场资源。而我国的GPGPU产品不仅在生态和开发领域面临着国外大厂卡脖子的挑战,即使是在各自的芯片研发领域也面临着研发周期长、投入量大、产品成功概率偏低等一系列问题。我国以CPU和GPU为代表的高端芯片设计行业的整体研发实力、创新能力和应用推广能力仍有待提升。面对事关未来时代变革的重要产品,或许需要政府、高校和研发企业共同努力,互相共享经验和成果,才能真正在这一领域缩小与国外的差距,实现真正的国产替代、自主可控。
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。
