OpenAI“政变”进行时,“百模大战”接下来该战什么?互联网+
脑极体
2023-11-22 11:58
导读
这两天AI圈最热闹的消息,应该就OpenAI高层内讧,标志性人物、原CEO Sam Altman被董事会解雇,数位科学家
这两天AI圈最热闹的消息,应该就OpenAI高层内讧,标志性人物、原CEO Sam Altman被董事会解雇,数位科学家和高层离职。
这两天AI圈最热闹的消息,应该就OpenAI高层内讧,标志性人物、原CEO Sam Altman被董事会解雇,数位科学家和高层离职。
关于“政变”的原因,坊间有很多传言,比如商业化和非营利原则的矛盾。总之,事件相关者在舆论场拉扯,吃瓜群众则瞪大了眼睛看戏。这场风波会给全球AI研发,尤其是大模型带来什么影响,还是未知数。
有人做了一个梗图,大模型厂商乱成一锅粥,只有卖卡的英伟达稳坐钓鱼台。
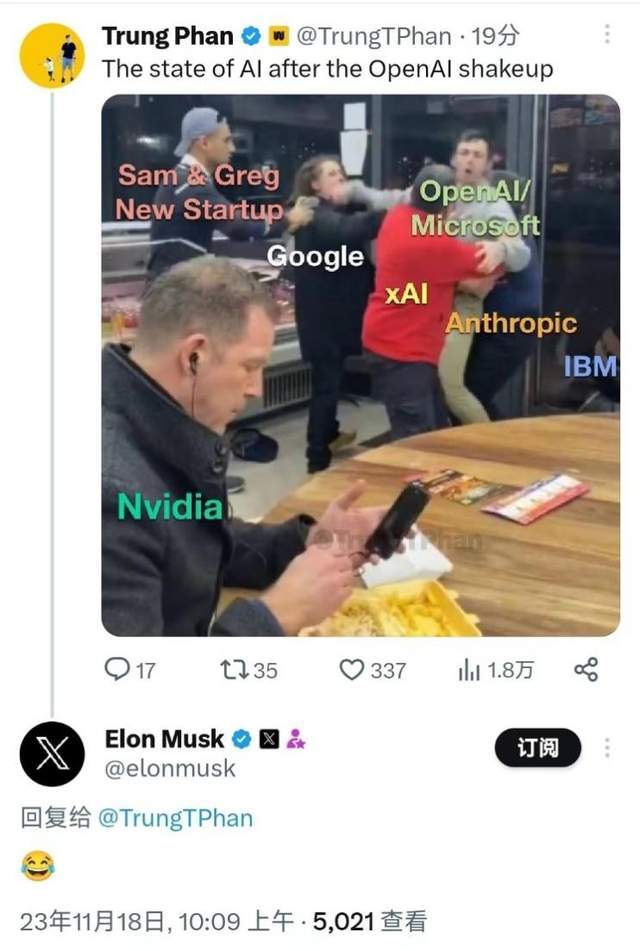 任它天边云卷云舒,可以肯定的是,中国的AI大模型在取得广泛成就的基础上,会继续向前发展,释放产业价值,并且不会一味照搬海外,尤其是OpenAI的模式。
带着这份淡定,我们将目光聚焦在国产大模型,会发现“百模大战”热潮中,还缺乏对各类大模型全面、分层、真实的能力评估。
通用大模型、行业大模型,都在比拼参数规模,但训练数据质量不确定,仅凭参数,行业客户和用户也难以选对适合的大模型。
那么看榜单呢?基准测试benchmark和标准化数据集,可以针对性调优,榜单无法反映实际应用效果差距。
而且大模型在不同任务场景下,表现的区分度很大。一位开发者说,“现在就是告诉你都有哪些大模型,实际效果还是得靠自己测测看”。
据中国信通院的数据显示,目前的大模型测试方法和数据集已有200多个。想要一个个测过来,会给用户带来非常繁重的工作量。
“百模大战”乱花渐欲迷人眼,那么,除了“跑分”打榜和参数“碾压”,还有什么办法来真实且有效地评判一个大模型的水平呢?
有必要来聊聊,“百模大战”,不同赛道都在战什么?
大模型,不看高分看高能
所谓“百模大战”,并不是每个大模型都在做着同样的事。其中,既有想做基座模型basemodle的通用大模型,如百度的文心、阿里的通义、腾讯的混元、华为的盘古、讯飞的星火、智谱的ChatGLM等,也有面向行业、场景的垂直大模型,目前在金融、教育、工业、传媒、政务等多个领域都大量涌现。
不同赛道的大模型,其核心竞争力也不一样。比如一味拼算法的打榜,对于行业大模型来说,可以作为一种宣传手段和“炫技”,但实际效果才是用户最关注的。
目前不少开发者反映,各类大模型都存在各自的问题。
1.基座模型,本身能力有限制。
提到通用大模型,大家可能第一时间想到的就是推理能力,这也是大模型基准测试的主要指标。但在实际应用中,尤其是文科类型任务,大家不会没事出“脑筋急转弯”来测试通用大模型的逻辑推理能力,而是更希望大模型在复杂任务和上下文长度上,有更可靠的表现。
任它天边云卷云舒,可以肯定的是,中国的AI大模型在取得广泛成就的基础上,会继续向前发展,释放产业价值,并且不会一味照搬海外,尤其是OpenAI的模式。
带着这份淡定,我们将目光聚焦在国产大模型,会发现“百模大战”热潮中,还缺乏对各类大模型全面、分层、真实的能力评估。
通用大模型、行业大模型,都在比拼参数规模,但训练数据质量不确定,仅凭参数,行业客户和用户也难以选对适合的大模型。
那么看榜单呢?基准测试benchmark和标准化数据集,可以针对性调优,榜单无法反映实际应用效果差距。
而且大模型在不同任务场景下,表现的区分度很大。一位开发者说,“现在就是告诉你都有哪些大模型,实际效果还是得靠自己测测看”。
据中国信通院的数据显示,目前的大模型测试方法和数据集已有200多个。想要一个个测过来,会给用户带来非常繁重的工作量。
“百模大战”乱花渐欲迷人眼,那么,除了“跑分”打榜和参数“碾压”,还有什么办法来真实且有效地评判一个大模型的水平呢?
有必要来聊聊,“百模大战”,不同赛道都在战什么?
大模型,不看高分看高能
所谓“百模大战”,并不是每个大模型都在做着同样的事。其中,既有想做基座模型basemodle的通用大模型,如百度的文心、阿里的通义、腾讯的混元、华为的盘古、讯飞的星火、智谱的ChatGLM等,也有面向行业、场景的垂直大模型,目前在金融、教育、工业、传媒、政务等多个领域都大量涌现。
不同赛道的大模型,其核心竞争力也不一样。比如一味拼算法的打榜,对于行业大模型来说,可以作为一种宣传手段和“炫技”,但实际效果才是用户最关注的。
目前不少开发者反映,各类大模型都存在各自的问题。
1.基座模型,本身能力有限制。
提到通用大模型,大家可能第一时间想到的就是推理能力,这也是大模型基准测试的主要指标。但在实际应用中,尤其是文科类型任务,大家不会没事出“脑筋急转弯”来测试通用大模型的逻辑推理能力,而是更希望大模型在复杂任务和上下文长度上,有更可靠的表现。
 比如写一篇演讲文稿,篇幅一长就开始胡说八道或泛泛而谈,文本的采用率下降;为AIGC配字幕,不能整篇生成,还需要人工将文案切割成片;编写一个程序,半路开始network error……这些都是实际应用中,大家比较关注的通用大模型的能力。
2.行业大模型,领域壁垒难翻越。
“百模大战”进行到当下,很多行业开发者和企业都意识到,独有的数据和场景,才是自己的护城河,开始打造定制化的大模型,而领域知识不够,难以形成满足某一领域需求的行业向产品。
比如大模型与行业知识不匹配、许多行业know-how还没有知识化、传统的知识图谱与大模型的协同设计等,知识计算的能力不够强,就无法真正撼动领域壁垒,让大模型解决实际的业务问题。
3.有用性,ROI是个谜。
大模型的实际应用效果难以评估,其中一个主要原因,就是模型生成结果的有用性(采用率、可用率等指标),涉及大量多模态数据。
金融、医药、交通、城市等产业中,存在着大量多模态信息,比如客服电话的语音、医学影像图片、传感器数据等,大语言模型必须具备多模态理解能力,将多模态信息与语言进行综合分析处理,才能保证较高质量的输出。
比如写一篇演讲文稿,篇幅一长就开始胡说八道或泛泛而谈,文本的采用率下降;为AIGC配字幕,不能整篇生成,还需要人工将文案切割成片;编写一个程序,半路开始network error……这些都是实际应用中,大家比较关注的通用大模型的能力。
2.行业大模型,领域壁垒难翻越。
“百模大战”进行到当下,很多行业开发者和企业都意识到,独有的数据和场景,才是自己的护城河,开始打造定制化的大模型,而领域知识不够,难以形成满足某一领域需求的行业向产品。
比如大模型与行业知识不匹配、许多行业know-how还没有知识化、传统的知识图谱与大模型的协同设计等,知识计算的能力不够强,就无法真正撼动领域壁垒,让大模型解决实际的业务问题。
3.有用性,ROI是个谜。
大模型的实际应用效果难以评估,其中一个主要原因,就是模型生成结果的有用性(采用率、可用率等指标),涉及大量多模态数据。
金融、医药、交通、城市等产业中,存在着大量多模态信息,比如客服电话的语音、医学影像图片、传感器数据等,大语言模型必须具备多模态理解能力,将多模态信息与语言进行综合分析处理,才能保证较高质量的输出。
 在实际任务中,上述三种问题可能会同时存在,要同时解决。
一位医药专家告诉我,在研发医学影像的算法时,就需要基座大模型在预训练阶段就具备多模态理解能力、医学影像知识,可以执行通用任务。同时,行业侧还需要根据知识设计目标函数,在特征抽取、相似性度量、迭代优化算法等,都要贡献好各自的知识,才可能训练出一个对医务工作者友好的领域大模型,不需要专业知识,也不需要建模,就能上手使用。
就像工业革命的开始,是因为瓦特改良了蒸汽机。在此之前,蒸汽机早已被发明出来了,但一直没有解决大规模高可用的问题,大模型也是如此。
大模型产业化,必须从基准测试的“跑高分”,向可信赖的“高能力”进化。
百模大战,究竟在战哪些能力?
从高分到高能,让大模型具有与行业结合的可行性,也让“百模大战”正在进入新的阶段。
从产业实际需求来看,可用且有效的大模型,至少应该具备几个核心能力:
1.长文能力。
大语言模型的技术特点,被认为是“鹦鹉学舌”,将输入信号拼凑成有一定语法结构的句子,也就是文本补全能力。而大模型都有“幻觉”,上下文窗口的长度增加,逻辑幻觉就可能越严重,“鹦鹉学舌”开始变得吃力。
在很多垂直行业应用中,如金融、法律、财务、营销等,长文档的分析处理和生成能力是刚需。
在实际任务中,上述三种问题可能会同时存在,要同时解决。
一位医药专家告诉我,在研发医学影像的算法时,就需要基座大模型在预训练阶段就具备多模态理解能力、医学影像知识,可以执行通用任务。同时,行业侧还需要根据知识设计目标函数,在特征抽取、相似性度量、迭代优化算法等,都要贡献好各自的知识,才可能训练出一个对医务工作者友好的领域大模型,不需要专业知识,也不需要建模,就能上手使用。
就像工业革命的开始,是因为瓦特改良了蒸汽机。在此之前,蒸汽机早已被发明出来了,但一直没有解决大规模高可用的问题,大模型也是如此。
大模型产业化,必须从基准测试的“跑高分”,向可信赖的“高能力”进化。
百模大战,究竟在战哪些能力?
从高分到高能,让大模型具有与行业结合的可行性,也让“百模大战”正在进入新的阶段。
从产业实际需求来看,可用且有效的大模型,至少应该具备几个核心能力:
1.长文能力。
大语言模型的技术特点,被认为是“鹦鹉学舌”,将输入信号拼凑成有一定语法结构的句子,也就是文本补全能力。而大模型都有“幻觉”,上下文窗口的长度增加,逻辑幻觉就可能越严重,“鹦鹉学舌”开始变得吃力。
在很多垂直行业应用中,如金融、法律、财务、营销等,长文档的分析处理和生成能力是刚需。
 在长文中保持逻辑的连贯性、合理性,考验着大模型的综合能力,比如对复杂语句的理解及记忆能力,生成的可靠性,这也是大模型走向产业化的核心。
目前,无论开源、闭源大模型,都将长文能力作为一个核心竞争力。比如流行的开源大模型Llama 2,就将上下文长度扩展至 128k,而基于LLaMA架构的零一万物的Yi系列大模型,此前曾宣称拿下了全球最长上下文窗口宝座,达到200K,可直接处理40万汉字超长文本输入。闭源大模型中,GPT-4 Turbo支持了比ChatGPT更长的上下文(128k tokens),百度的文心大模型通过对话增强,提升上下文理解能力。
2.知识能力。
大模型“大力出奇迹”的模式,忽略了模型准确感知和理解注入知识的能力,目前已经凸显了很多问题。比如不理解领域知识,在实际业务中表现不佳,无法满足ToB用户的需求。因此,当欧美科技公司依然在执着追求更大参数时,百度、华为等国内大模型厂商,开始转向了行业场景,将强业务知识引入文心、盘古的行业大模型之中,来提升大模型在行业任务中的应用效果。
具体是怎么做的呢?以“行业知识增强”为核心特色的文心,是在预训练大模型的基础上,进一步融合大规模知识图谱,挖掘行业应用场景中大量存在的行业特色数据与知识,再结合行业专家的知识,从大规模知识和海量数据中融合学习,把知识内化至模型参数中。
在长文中保持逻辑的连贯性、合理性,考验着大模型的综合能力,比如对复杂语句的理解及记忆能力,生成的可靠性,这也是大模型走向产业化的核心。
目前,无论开源、闭源大模型,都将长文能力作为一个核心竞争力。比如流行的开源大模型Llama 2,就将上下文长度扩展至 128k,而基于LLaMA架构的零一万物的Yi系列大模型,此前曾宣称拿下了全球最长上下文窗口宝座,达到200K,可直接处理40万汉字超长文本输入。闭源大模型中,GPT-4 Turbo支持了比ChatGPT更长的上下文(128k tokens),百度的文心大模型通过对话增强,提升上下文理解能力。
2.知识能力。
大模型“大力出奇迹”的模式,忽略了模型准确感知和理解注入知识的能力,目前已经凸显了很多问题。比如不理解领域知识,在实际业务中表现不佳,无法满足ToB用户的需求。因此,当欧美科技公司依然在执着追求更大参数时,百度、华为等国内大模型厂商,开始转向了行业场景,将强业务知识引入文心、盘古的行业大模型之中,来提升大模型在行业任务中的应用效果。
具体是怎么做的呢?以“行业知识增强”为核心特色的文心,是在预训练大模型的基础上,进一步融合大规模知识图谱,挖掘行业应用场景中大量存在的行业特色数据与知识,再结合行业专家的知识,从大规模知识和海量数据中融合学习,把知识内化至模型参数中。
 当用户输入问题时,文心4.0会拆解回答问题所需的知识点,进而在搜索引擎、知识图谱、数据库中查找准确知识,再将知识组装进Prompt送入大模型。另一方面,大模型还将对输出结果进行反思,从生成结果总结知识点,进而通过以上方式进行确认验证,对结果差错进行修正。
目前来看,在同等参数规模下,知识增强的深度语意理解,效果大幅超越了纯粹用深度学习的方法,推理效率更高,并且可解释性更强,更符合产业对可信AI的需求。
目前,知识+大模型还有许多细节有待解决,比如知识体系的构建,知识的持续获取,知识应用和推理等,这些问题的攻克都会给行业认知智能带来重大机会。
3.多模态能力。
2022年我参加华为云AI院长峰会,一位科学家提到,大模型有一个问题,就是有很多符号领域,大模型根本就不理解。他认为,大模型是数据与知识双轮驱动的,双轮驱动是未来人工智能发展的重要模式。
前面我们说了知识能力的重要性,那么“数据”究竟拼的是什么呢?就是多模态能力。
把大模型应用到领域的时候,会发现问题非常多,根本达不到预期的效果。一个主要原因,大语言模型完全是基于语言的,而真实世界的复杂任务,有大量的数值、图表、语音、视频等多模态数据,数据的多模态特性增加了模型处理、建模和推理的复杂性。
当用户输入问题时,文心4.0会拆解回答问题所需的知识点,进而在搜索引擎、知识图谱、数据库中查找准确知识,再将知识组装进Prompt送入大模型。另一方面,大模型还将对输出结果进行反思,从生成结果总结知识点,进而通过以上方式进行确认验证,对结果差错进行修正。
目前来看,在同等参数规模下,知识增强的深度语意理解,效果大幅超越了纯粹用深度学习的方法,推理效率更高,并且可解释性更强,更符合产业对可信AI的需求。
目前,知识+大模型还有许多细节有待解决,比如知识体系的构建,知识的持续获取,知识应用和推理等,这些问题的攻克都会给行业认知智能带来重大机会。
3.多模态能力。
2022年我参加华为云AI院长峰会,一位科学家提到,大模型有一个问题,就是有很多符号领域,大模型根本就不理解。他认为,大模型是数据与知识双轮驱动的,双轮驱动是未来人工智能发展的重要模式。
前面我们说了知识能力的重要性,那么“数据”究竟拼的是什么呢?就是多模态能力。
把大模型应用到领域的时候,会发现问题非常多,根本达不到预期的效果。一个主要原因,大语言模型完全是基于语言的,而真实世界的复杂任务,有大量的数值、图表、语音、视频等多模态数据,数据的多模态特性增加了模型处理、建模和推理的复杂性。
 一位医疗模型的开发者告诉我,医疗任务分析非常繁杂,数量级很多,有不同模态、病种,每一种模态有不同的诊疗任务,要把文本、图像等多模态包容过来,而医疗领域非常缺少多模态的预训练模型。
大模型要在实际业务中达到与人更接近的能力,也需要跨模态建立统一认知。
举个例子,AIGC生成营销活动物料,根据文字描述生成图像、视频,既要精确理解提示词的语义,还要符合领域规范,不能出现不合规的素材,同时要控制生成内容的质量,保持跨模态的语义一致性。
国产大模型在多模态领域也做了很多差异化探索,除了大家熟悉的以文生图,在医疗影像、遥感、抗体药物、交通等领域,跨模态技术融合也在快速开展,未来会是基座大模型和行业大模型的亮点。
一位医疗模型的开发者告诉我,医疗任务分析非常繁杂,数量级很多,有不同模态、病种,每一种模态有不同的诊疗任务,要把文本、图像等多模态包容过来,而医疗领域非常缺少多模态的预训练模型。
大模型要在实际业务中达到与人更接近的能力,也需要跨模态建立统一认知。
举个例子,AIGC生成营销活动物料,根据文字描述生成图像、视频,既要精确理解提示词的语义,还要符合领域规范,不能出现不合规的素材,同时要控制生成内容的质量,保持跨模态的语义一致性。
国产大模型在多模态领域也做了很多差异化探索,除了大家熟悉的以文生图,在医疗影像、遥感、抗体药物、交通等领域,跨模态技术融合也在快速开展,未来会是基座大模型和行业大模型的亮点。
 从这些产业需要的能力来看,大模型的产业属性和价值已经清晰展露了出来。
大模型,绝不是聊聊天、搞怪图片那么肤浅,技术覆盖区域是很广阔的,技术应用价值已经足够具有说服力。
但也必须承认,目前,绝大多数产业所获取的技术能力和技术深度,都还远远不够。一方面受限于上游的基座大模型能力,同时也缺乏深度定制化的中游服务商,导致用户大多只能调用简单化、标准化的API,而难以将领域知识、多模态数据与大模型深度结合。
未来,从高分到高能,国产大模型一定会依靠自身的差异化技术路线,以及中国丰富多样的产业需求,从懵懂走向成熟,甚至先于欧美,走向千行百业
从这些产业需要的能力来看,大模型的产业属性和价值已经清晰展露了出来。
大模型,绝不是聊聊天、搞怪图片那么肤浅,技术覆盖区域是很广阔的,技术应用价值已经足够具有说服力。
但也必须承认,目前,绝大多数产业所获取的技术能力和技术深度,都还远远不够。一方面受限于上游的基座大模型能力,同时也缺乏深度定制化的中游服务商,导致用户大多只能调用简单化、标准化的API,而难以将领域知识、多模态数据与大模型深度结合。
未来,从高分到高能,国产大模型一定会依靠自身的差异化技术路线,以及中国丰富多样的产业需求,从懵懂走向成熟,甚至先于欧美,走向千行百业
任它天边云卷云舒,可以肯定的是,中国的AI大模型在取得广泛成就的基础上,会继续向前发展,释放产业价值,并且不会一味照搬海外,尤其是OpenAI的模式。
带着这份淡定,我们将目光聚焦在国产大模型,会发现“百模大战”热潮中,还缺乏对各类大模型全面、分层、真实的能力评估。
通用大模型、行业大模型,都在比拼参数规模,但训练数据质量不确定,仅凭参数,行业客户和用户也难以选对适合的大模型。
那么看榜单呢?基准测试benchmark和标准化数据集,可以针对性调优,榜单无法反映实际应用效果差距。
而且大模型在不同任务场景下,表现的区分度很大。一位开发者说,“现在就是告诉你都有哪些大模型,实际效果还是得靠自己测测看”。
据中国信通院的数据显示,目前的大模型测试方法和数据集已有200多个。想要一个个测过来,会给用户带来非常繁重的工作量。
“百模大战”乱花渐欲迷人眼,那么,除了“跑分”打榜和参数“碾压”,还有什么办法来真实且有效地评判一个大模型的水平呢?
有必要来聊聊,“百模大战”,不同赛道都在战什么?
大模型,不看高分看高能
所谓“百模大战”,并不是每个大模型都在做着同样的事。其中,既有想做基座模型basemodle的通用大模型,如百度的文心、阿里的通义、腾讯的混元、华为的盘古、讯飞的星火、智谱的ChatGLM等,也有面向行业、场景的垂直大模型,目前在金融、教育、工业、传媒、政务等多个领域都大量涌现。
不同赛道的大模型,其核心竞争力也不一样。比如一味拼算法的打榜,对于行业大模型来说,可以作为一种宣传手段和“炫技”,但实际效果才是用户最关注的。
目前不少开发者反映,各类大模型都存在各自的问题。
1.基座模型,本身能力有限制。
提到通用大模型,大家可能第一时间想到的就是推理能力,这也是大模型基准测试的主要指标。但在实际应用中,尤其是文科类型任务,大家不会没事出“脑筋急转弯”来测试通用大模型的逻辑推理能力,而是更希望大模型在复杂任务和上下文长度上,有更可靠的表现。
比如写一篇演讲文稿,篇幅一长就开始胡说八道或泛泛而谈,文本的采用率下降;为AIGC配字幕,不能整篇生成,还需要人工将文案切割成片;编写一个程序,半路开始network error……这些都是实际应用中,大家比较关注的通用大模型的能力。
2.行业大模型,领域壁垒难翻越。
“百模大战”进行到当下,很多行业开发者和企业都意识到,独有的数据和场景,才是自己的护城河,开始打造定制化的大模型,而领域知识不够,难以形成满足某一领域需求的行业向产品。
比如大模型与行业知识不匹配、许多行业know-how还没有知识化、传统的知识图谱与大模型的协同设计等,知识计算的能力不够强,就无法真正撼动领域壁垒,让大模型解决实际的业务问题。
3.有用性,ROI是个谜。
大模型的实际应用效果难以评估,其中一个主要原因,就是模型生成结果的有用性(采用率、可用率等指标),涉及大量多模态数据。
金融、医药、交通、城市等产业中,存在着大量多模态信息,比如客服电话的语音、医学影像图片、传感器数据等,大语言模型必须具备多模态理解能力,将多模态信息与语言进行综合分析处理,才能保证较高质量的输出。
在实际任务中,上述三种问题可能会同时存在,要同时解决。
一位医药专家告诉我,在研发医学影像的算法时,就需要基座大模型在预训练阶段就具备多模态理解能力、医学影像知识,可以执行通用任务。同时,行业侧还需要根据知识设计目标函数,在特征抽取、相似性度量、迭代优化算法等,都要贡献好各自的知识,才可能训练出一个对医务工作者友好的领域大模型,不需要专业知识,也不需要建模,就能上手使用。
就像工业革命的开始,是因为瓦特改良了蒸汽机。在此之前,蒸汽机早已被发明出来了,但一直没有解决大规模高可用的问题,大模型也是如此。
大模型产业化,必须从基准测试的“跑高分”,向可信赖的“高能力”进化。
百模大战,究竟在战哪些能力?
从高分到高能,让大模型具有与行业结合的可行性,也让“百模大战”正在进入新的阶段。
从产业实际需求来看,可用且有效的大模型,至少应该具备几个核心能力:
1.长文能力。
大语言模型的技术特点,被认为是“鹦鹉学舌”,将输入信号拼凑成有一定语法结构的句子,也就是文本补全能力。而大模型都有“幻觉”,上下文窗口的长度增加,逻辑幻觉就可能越严重,“鹦鹉学舌”开始变得吃力。
在很多垂直行业应用中,如金融、法律、财务、营销等,长文档的分析处理和生成能力是刚需。
在长文中保持逻辑的连贯性、合理性,考验着大模型的综合能力,比如对复杂语句的理解及记忆能力,生成的可靠性,这也是大模型走向产业化的核心。
目前,无论开源、闭源大模型,都将长文能力作为一个核心竞争力。比如流行的开源大模型Llama 2,就将上下文长度扩展至 128k,而基于LLaMA架构的零一万物的Yi系列大模型,此前曾宣称拿下了全球最长上下文窗口宝座,达到200K,可直接处理40万汉字超长文本输入。闭源大模型中,GPT-4 Turbo支持了比ChatGPT更长的上下文(128k tokens),百度的文心大模型通过对话增强,提升上下文理解能力。
2.知识能力。
大模型“大力出奇迹”的模式,忽略了模型准确感知和理解注入知识的能力,目前已经凸显了很多问题。比如不理解领域知识,在实际业务中表现不佳,无法满足ToB用户的需求。因此,当欧美科技公司依然在执着追求更大参数时,百度、华为等国内大模型厂商,开始转向了行业场景,将强业务知识引入文心、盘古的行业大模型之中,来提升大模型在行业任务中的应用效果。
具体是怎么做的呢?以“行业知识增强”为核心特色的文心,是在预训练大模型的基础上,进一步融合大规模知识图谱,挖掘行业应用场景中大量存在的行业特色数据与知识,再结合行业专家的知识,从大规模知识和海量数据中融合学习,把知识内化至模型参数中。
当用户输入问题时,文心4.0会拆解回答问题所需的知识点,进而在搜索引擎、知识图谱、数据库中查找准确知识,再将知识组装进Prompt送入大模型。另一方面,大模型还将对输出结果进行反思,从生成结果总结知识点,进而通过以上方式进行确认验证,对结果差错进行修正。
目前来看,在同等参数规模下,知识增强的深度语意理解,效果大幅超越了纯粹用深度学习的方法,推理效率更高,并且可解释性更强,更符合产业对可信AI的需求。
目前,知识+大模型还有许多细节有待解决,比如知识体系的构建,知识的持续获取,知识应用和推理等,这些问题的攻克都会给行业认知智能带来重大机会。
3.多模态能力。
2022年我参加华为云AI院长峰会,一位科学家提到,大模型有一个问题,就是有很多符号领域,大模型根本就不理解。他认为,大模型是数据与知识双轮驱动的,双轮驱动是未来人工智能发展的重要模式。
前面我们说了知识能力的重要性,那么“数据”究竟拼的是什么呢?就是多模态能力。
把大模型应用到领域的时候,会发现问题非常多,根本达不到预期的效果。一个主要原因,大语言模型完全是基于语言的,而真实世界的复杂任务,有大量的数值、图表、语音、视频等多模态数据,数据的多模态特性增加了模型处理、建模和推理的复杂性。
一位医疗模型的开发者告诉我,医疗任务分析非常繁杂,数量级很多,有不同模态、病种,每一种模态有不同的诊疗任务,要把文本、图像等多模态包容过来,而医疗领域非常缺少多模态的预训练模型。
大模型要在实际业务中达到与人更接近的能力,也需要跨模态建立统一认知。
举个例子,AIGC生成营销活动物料,根据文字描述生成图像、视频,既要精确理解提示词的语义,还要符合领域规范,不能出现不合规的素材,同时要控制生成内容的质量,保持跨模态的语义一致性。
国产大模型在多模态领域也做了很多差异化探索,除了大家熟悉的以文生图,在医疗影像、遥感、抗体药物、交通等领域,跨模态技术融合也在快速开展,未来会是基座大模型和行业大模型的亮点。
从这些产业需要的能力来看,大模型的产业属性和价值已经清晰展露了出来。
大模型,绝不是聊聊天、搞怪图片那么肤浅,技术覆盖区域是很广阔的,技术应用价值已经足够具有说服力。
但也必须承认,目前,绝大多数产业所获取的技术能力和技术深度,都还远远不够。一方面受限于上游的基座大模型能力,同时也缺乏深度定制化的中游服务商,导致用户大多只能调用简单化、标准化的API,而难以将领域知识、多模态数据与大模型深度结合。
未来,从高分到高能,国产大模型一定会依靠自身的差异化技术路线,以及中国丰富多样的产业需求,从懵懂走向成熟,甚至先于欧美,走向千行百业
模型
能力
知识
行业
领域
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。
