画风“快手味浓”、应用前景不明朗:可灵难成快手“灵丹妙药”快讯
打出“中国版Sora”旗号,快手迅速攻入文生视频大模型领域。

作者|冰拿铁
编辑|方奇
媒体|AI大模型工场
打出“中国版Sora”旗号,快手迅速攻入文生视频大模型领域。6月6日,“可灵”视频生成大模型官网正式上线, 生成的视频分辨率高达1080p,时长最高可达2分钟(帧率30fps);6月21日,可灵再添筹码,宣布推出图生视频功能。
在开放公测后,一众业内人士和吃瓜群众迅速涌入,在快手旗下创作工具快影 App申请,一试可灵“到底灵不灵”。而汇集多项测评及反馈,可以看到,可灵在技术上还和Sora有一定差距,除了语义理解问题、生成画面不符合物理世界规律、真实性差等“硬伤”外,“画风质感一言难尽”“美观性欠佳”“快手味过浓”也是被频繁提及的关键词。
一言以蔽之,正如当年依靠下沉市场异军突起的路径,快手如今在AI界,又一次展现出惊人相似的气质——基本功底不差,但仍然难逃“下沉”标签与命运。
存在语义理解、画风质感等多薄弱环节:
可灵难逃“下沉”标签?
在架构选择上,可灵紧跟Sora步伐。据快手大模型团队介绍,其采用类似 Sora 模型的 DiT 结构,用Transformer代替了传统扩散模型中基于卷积网络的U-Net,这也是当下文生视频领域的主流趋势——过去几年,基于U-Net架构的扩散模型暴露出无法处理复杂指令等问题,而Diffusion Transformer在处理大规模视觉数据方面具有显著优势,能够生成更为复杂和连贯的视频内容。
基于此,可灵整体表现不会太差,然而,在进一步功力比拼中,可灵的短板逐渐暴露。
首先,是语义理解层面,在知乎“如何看待中国版Sora可灵爆火”这一问题下,有网友表示,输入“一只大熊猫在开心地吃粽子”,结果生成了熊猫在吃水饺;再比如,想生成猫咪赛龙舟的场景,输入“一群猫咪坐在龙舟里”,结果生成的视频中没有猫咪,只有人。
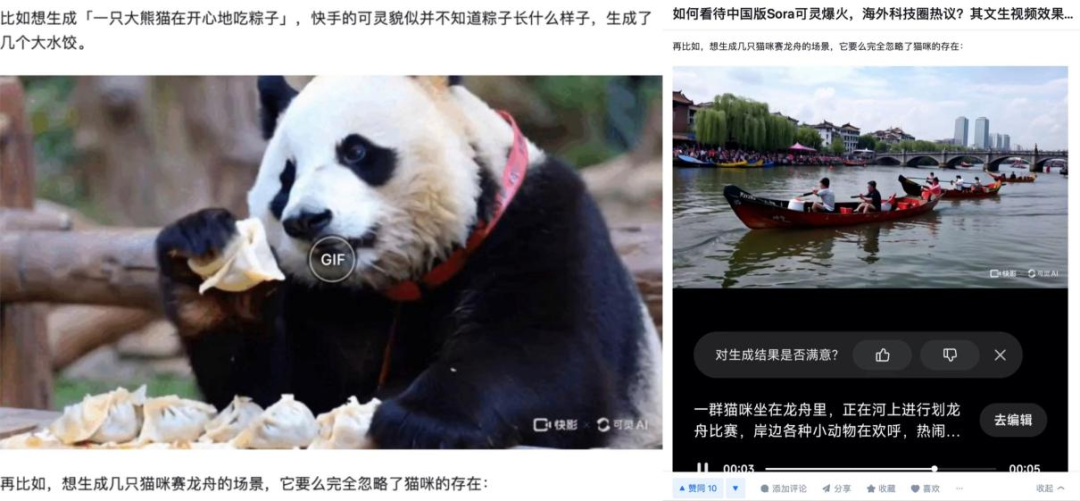
而这背后,则显露出可灵在语义理解能力的与细节捕捉能力的功力不足:无论是无法分别出“人类”和“猫咪”的区别,还是混淆“粽子”和“水饺”,都意味着着可灵在语义层面上存在理解偏差,无法精确捕捉输入描述中的关键信息,尤其是在处理非常规或特定领域的对象时,语义解析层面还有提升空间。
再往前追溯,可灵在构建视频场景时,可能受限于其训练数据和算法能力,无法准确地将文字描述转化为符合预期的视觉内容:
训练过程中,可灵所依赖的数据集或缺乏足够的“赛龙舟”等特定场景的数据,导致模型无法准确学习并生成相关视频,此外,训练策略可能没有针对细节进行足够的优化,让模型未能充分学习到“人类与猫咪”等不同对象之间的区别和特征。
再比如,据《每日经济新闻》测评,在一些视频生成时,可灵存在诸多“失灵”时刻。例如,弹吉他的熊猫拥有人类的手指;提示词中“浅绿色的布艺沙发”,到了视频中呈现的则是红棕色的皮质沙发。同时,在一些视频中,当有多个主体时,有时也会出现一些元素无法完全呈现在视频中的情况。

事实上,台上一分钟的文生视频秀肌肉背后,比拼的是“台下十年功”的训练积累。这也是为什么,大差不差的架构下,可灵生成的视频有诸多“bug”。
正如此前,一览科技创始人罗江春公开表示,国内生成式视频大模型面临的最大挑战,本质上是底层能力的差距,这个底层能力包括数据、模型和算力:“我们有能力追上Sora今天的效果,但是当追上的时候,Sora又已经往前走了一大步,这个差距会保持比较长一段时间。”
除了硬伤外,可灵的画风更是被诟病最多的地方。在同样的提示词下,可灵和Sora生成的画风对比“一言难尽”。
拿让Sora迅速爆火出圈的那段视频来说,提示词为“一位时尚的女人走在东京的街道上,街道上到处都是温暖的发光霓虹灯和动画城市标志,她背着一个黑色钱包。她戴着墨镜,涂着红色口红。她自信而随意地走路。街道潮湿而反光,营造出五颜六色的灯光的镜面效果,许多行人四处走动。”
而有网友把同样的提示词投喂给可灵,生成的视频却极为“快手风”:
歪嘴女主角迈着六亲不认的步伐,穿着看上去正常但凑在一起就莫名土味的穿搭,走出了精神小妹进城讨债的气势,背后还有紧身裤小伙乱入,整个街道也有一种浓浓的城乡结合部既视感。让人不禁想配一段社会语录,比如“精致小包怀里夹,开上我的小捷达”“大姐走路就这么der,好像赵四跳皮筋”之类的。

在社交平台上,也有很多网友表示“生成的画风很古早”“有点土”“果然是快手做出来的东西,有一种快手味”。

归根结底,画风质感差的背后,是数据集质量与多样性直接影响模型的输出效果——如果训练数据中包含大量低质量或风格单一的图像或视频,缺乏现代、时尚或特定艺术风格的样本,模型就很难学习到高质量、多样化的画风,导致生成时很难跳出固有的画风框架。
同时,在生成过程中,模型可能没有足够的约束条件来确保生成内容的风格一致性、细节丰富度和整体美感;优化算法也可能未能充分探索生成空间的潜力,导致生成结果趋于平庸或单一。
对此,也有行业人士对此做出了点评,如《麻省理工科技评论》报道,北京的一位人工智能艺术家Guizang表示,Kling 的劣势在于结果的美观性,比如构图或色彩分级:“但这不是什么大问题。这个问题可以很快解决。”
诚然,在当下,没有对比就没有伤害,占位国内头批开放公测的文生视频大模型,可灵的问题无伤大雅,然而在群雄环绕的赛道,可灵很难长期“一家独大”。
群雄环绕下,更多问题暴露:
可灵难成快手“灵丹妙药”
如今,文生视频领域并不缺实力派玩家。在今年2月Sora率先引爆全球后,文生视频领域产品呈雨后春笋之势全线爆发,众多产品和外界之间仅一墙之隔,就差“临门一脚”,即向公众开放了。
4月,生数科技发布文生视频大模型Vidu,可根据文本描述直接生成16s、分辨率高达1080P的高清视频内容;5月,腾讯表示,其立足DiT架构的混元大模型支持文生视频、图生视频、图文生视频、视频生视频等多种视频生成能力;6月,极佳科技联合清华大学发布中国首个端侧可用的Sora级视频生成大模型“视界一粟YiSu”,拥有模型原生的16秒时长,可生成1分钟以上视频……
随着技术不断完善,开放也逐渐被提上日程。6月30日,Runway向部分用户开放Gen-3使用权限;7月2日,Runway宣布,其文生视频模型Gen-3Alpha向所有用户开放,每个月最少12美元即可使用。
随着更多玩家纷纷揭开面纱,可灵头上“首个开放公测”的光环也将淡去,这时,一众技术真功夫比拼才刚刚开始。同时,对快手来说,重要的不是具有文生视频能力多强悍,而是如何将其与商业版图结合,推进落地应用。
在外界看来,作为短视频平台,快手天生拥有落地土壤,可以将“可灵”融入其创作者生态,进一步主推内容场域繁荣。而“可灵”的推出也一定程度上反映了快手的内容焦虑,据快手2024年Q1财报数据显示,报告期内,快手实际月活人数为6.97亿,环比下降0.4%,呈现流失趋势,2023年Q4时为7.004亿。
然而,AI创作并非内容的“灵丹妙药”——对用户来说,看AI创作的短视频更多是“看新鲜”“看热闹”,真正能产生黏性的仍然是真人主播及优质内容。
同时,随着可灵全面开放,在极大地降低短视频制作的综合成本和门槛的同时,也可能导致更多低质量、无底线内容涌现,某些视频甚至可能会被制作、滥用和恶意传播,成为部分犯罪分子进行电信诈骗、网络传销、敲诈勒索的工具,加大平台监管难度。
快手显然也明白这一点,今年6月,快手电商发布了使用AIGC能力直播的倡议公告,称“我们更希望看到真实的直播内容,鼓励商家/达人和老铁们进行实时良好的互动,建立更加深厚的情感,同时,有意利用AIGC的低成本优势生产出的低质量内容更是平台不愿意看到的内容生产行为”。因此,“使用AIGC能力辅助创作的内容相较于其他实时直播内容,平台不会给予特殊的流量扶持。”
事实上,C端看热闹,B端看门道,文生视频大模型真正的落地仍在产业端。如Sora接入了海外主流的大语言模型,通过学习爆款视频的文本结构,生成适合商家产品的文案和脚本,并自动与商家提供的产品素材匹配,一键生成视频。
而在我国,华为盘古大模型5.0的多模态能力包括了视频生成技术,并面向产业端落地,据华为常务董事、华为云CEO张平安介绍,华为将视频生成技术应用到了自动驾驶的训练环节;而字节跳动旗下的即梦则深入影视行业,今年6月,官宣其和博纳影业宣布联合出品的AIGC科幻短剧集《三星堆:未来启示录》作为首席AI技术支持方,即梦AI基于豆包大模型技术,提供了AI剧本创作、镜头画面生成等十种AI技术。
这也给可灵的应用落地提供了参考路径。显然,在从“精神大模型”到“AI灵丹妙药”的飞跃中,可灵还有一段路要走。
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。
