创新承压、洗牌持续,摩尔线程要做“国产英伟达”?快讯
成立于2020年10月的摩尔线程,在国内GPU厂商中属于相对低调的存在。直到2023年10月,美国商务部突然将摩尔线程列入贸易管制“黑名单”,摩尔线程才引发市场大量关注。
 撰文 | 曹双涛
撰文 | 曹双涛
编辑 | 杨博
丞题图 | IC Photo
上线4天销量超1000万套,全平台最高同时在线人数超300万人,Steam平台27万+评价,96%好评。国产首款3A游戏《黑神话:悟空》的火爆,带火的不仅只有山西,也有国产GPU厂商。
《黑神话:悟空》正式发售之际,摩尔线程发布的V270.80驱动程序已解决DirectX11模式下运行《黑神话:悟空》Benchmark时的闪退问题。大量玩家的关注,8月25日摩尔线程百度资讯指数达到近30天峰值。
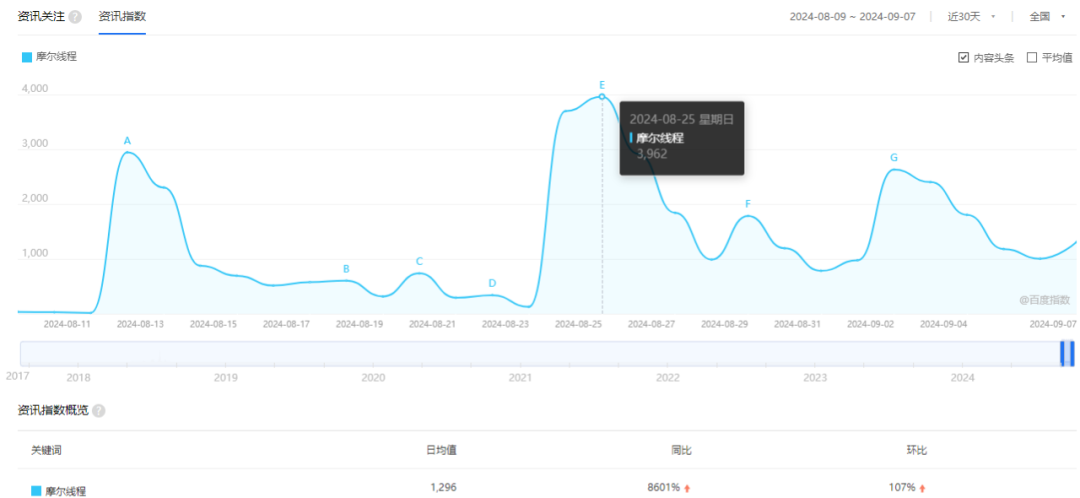 图源:百度指数
图源:百度指数
成立于2020年10月的摩尔线程,在国内GPU厂商中属于相对低调的存在。直到2023年10月,美国商务部突然将摩尔线程列入贸易管制“黑名单”,摩尔线程才引发市场大量关注。
但创投圈中,摩尔线程却属于“高调”的存在。摩尔线程不仅核心团队来自英伟达,且创始人张建中为原英伟达中国区总经理、英伟达全球副总裁。浓厚的英伟达基因以及近几年从高层到地方,对国产替代政策的大力支持,摩尔线程受到资本高度青睐。
据悉,摩尔线程成立至今完成的5轮融资中,每轮融资阵容都极其强大,资方涵盖上下游资本、头部机构、政府基金、战略投资等等。
 图源:天眼查
图源:天眼查
资本助推下,摩尔线程发展速度较快。围绕TOC端桌面显卡,摩尔线程现有产品包括MTT S80、S70、S50、S30、S10。围绕TOB端AI大模型,摩尔线程产品包括训推一体机MCCX D800、AI超融合一体机KUAE FUSION,用于部署服务器推理、训练。且支持LLaMA、GLM、Aquila、Baichuan、GPT、Bloom、玉言等各类主流大模型的开源。
换言之,摩尔线程已建立从芯片、板卡、服务器、集群到软件的全栈AI智算产品线,市场认为摩尔线程是国内仅有能从功能上对标英伟达的国产GPU芯片厂商。但持续补齐软件生态、AI大模型技术迭代速度快带来的技术持续创新压力,以及国内GPU市场正进入洗牌阶段,让摩尔线程真正成为英伟达仍需持续发力。
01.桌面显卡销量有限,生态体系搭建仍需发力
“其盛也,始则人畏之。甚则人恶之,极则群起而攻之”。这或许是当下英伟达的真实写照。
自2024年至今,英伟达先后引来欧盟、法国等多地监管机构调查,要求其提供相关销售等数据。市场此前曾传出法国反垄断机构对英伟达当地办公室展开突袭搜查,扣押部分物件和相关数据。
另据外媒报道,英伟达已收到美国司法部具有法律意义上的传票,正式对英伟达展开调查。受此影响,英伟达市值暴跌近2800亿美元,创下美股最高纪录。按照合同赔偿客户只是小事,英伟达后续开放诸多技术才是关键。习惯高调强势的黄仁勋未来将如何应对,成为全球科技产业关注的焦点。
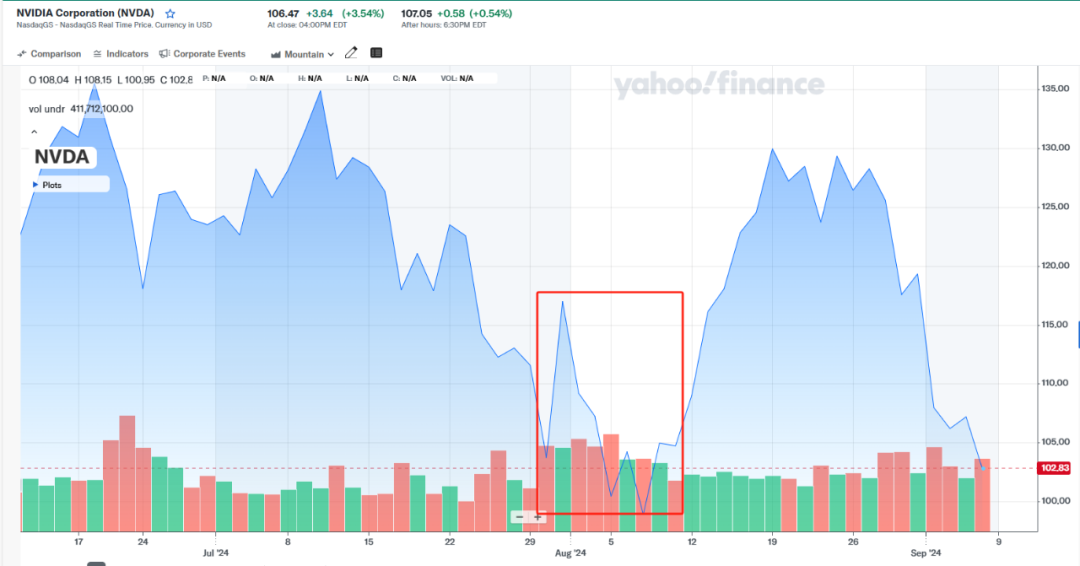 图源:Yahoo Finance
图源:Yahoo Finance
英伟达遭到全球多国调查,早在供应链预料范围内。服务器供应链表示,英伟达在AI GPU市占率高达九成,唯一同级对手就是AMD与Intel,但二者出货量和英伟达相比差距甚大。
在全球市场几乎没有对手的英伟达,不仅掌控者带下游客户的定价权、供货排期权。且上游难以取代的台积电以及富士康、广达等庞大供应链同样缺乏自主权。
但英伟达并不满足于此,一方面,通过技术持续升级、投资等多重方式,促进GPU产品的购买和使用,维持其竞争优势。
公开数据显示,自2023年至2024年8月底,英伟达参与投资数量高达74笔,涉及金额高达109亿美元。其中包括资料中心设计、开发和营运公司Applied Digital,Google技术人员在日本创立的Sakana AI等等。
另一方面,黄仁勋并不想让英伟达仅充当供应商角色,正试图将英伟达打造成数据中心所有关键元素的一站式服务平台——即AI工厂,以增加客户对英伟达产品的依赖。
面对英伟达难以撼动的地位及芯片短缺问题,国内以腾讯、阿里为代表的大厂依托资金和技术,加速推进自研AI芯片进程。比如腾讯自主研发的影片编解码芯片沧海已进入量产阶段,支持从云端游戏到视讯直播等服务。部分资金和技术实力欠佳的厂商,或选择租赁或选择从东南亚购入A100和H100系列芯片,后经香港流入国内市场。
此外,调整大模型的训练方式,成为不少厂商的策略之一。零一万物CEO创办人李开复提到,因缺乏足够GPU资源,他们只能开发出更高效的AI基础设施和推论引擎。这种低精度训练模式,同样被应用到美国海外大厂,核心优势在于加速模型的输出速度。
海外谷歌、OpenAl、微软等大厂除加速自研芯片进程外,近期微软、Google与英特尔等众多大厂携手成立Ultra Accelerator Link。UALink联盟成立的背后,正是想切断谷歌的生态护城河。
 图源:基于公开信息整理
图源:基于公开信息整理
服务器供应链表示,英伟达的护城河绝非只是多年累积的强大GPU技术和投入10多年研发的平行运算架构CUDA。2014年推出的NVLink以及NVSwitch交换器芯片等,让英伟达的GPU技术与生态系统更为强大与完整。CUDA为封闭生态系,只能在英伟达自家GPU上运行。NVLink同样为英伟达独家研发,竞争者只能采用现有PCIe等其他互连协定。
目前国内GPU产业面临核心且突出问题为缺乏类似英伟达CUDA的软件生态体系,虽说摩尔线程构建MUSA生态来兼容 CUDA,但京东平台不少已购MTT S80用户称,MTT S80因存在软件兼容问题、卡顿问题,可能并不适合新生小白使用。
 图源:京东
图源:京东
不少游戏玩家测评后发现,MTT S80实际表现与英伟达等一线大厂的显卡之间还有很大的差距。以黑神话测试工具的标准来看,MTT S80大致处于勉强能玩的样子。《黑神话:悟空》开服后,不少玩家也都反应打开游戏后出现黑屏、闪退的情况。
游戏玩家李阳(化名)告诉DoNews,在摩尔线程V270.80驱动版本以及1280*720p分辨率,《黑神话:悟空》的最高分辨率仅有20多帧,真正进入游戏后无法畅玩。
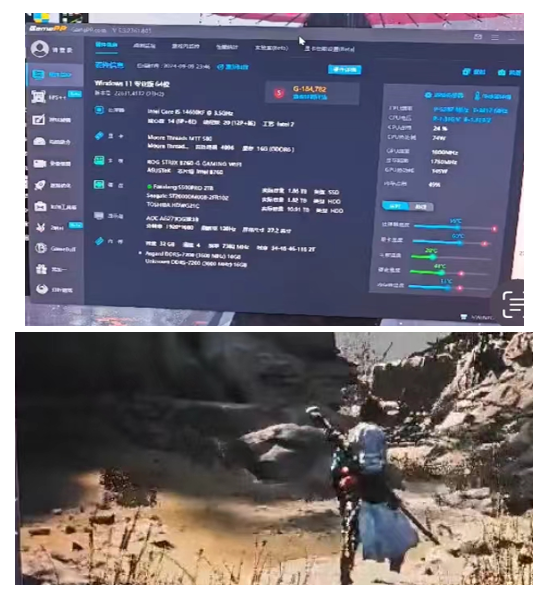 图源:受访者提供
图源:受访者提供
桌面显卡仍需提高的竞争力,直接影响到其桌面级显卡销量增长。京东官方旗舰店MTTS80评论量仅有2000+,其他显卡产品评论量更是不足2000+,这侧面说明摩尔线程桌面级显卡出货量欠佳。
另外,对标华为鸿蒙生态来看,从和APP厂商前期沟通到中期APP厂商排期、开发、测试,到最终完全上线,整个内容生态搭建不仅耗时较长且需厂商以庞大的销售团队和技术团队为支撑。
 图源:京东
图源:京东
不仅仅是软件生态,芯片互联同样是一大问题。联发科CEO蔡力直言,从整个系统角度来看,芯片之间的互联技术是除运算部分之外发展的最大瓶颈。换言之,如何持续攻克软硬件问题,或许是摩尔线程这家相对年轻的GPU企业需长期解决的问题。
02.大模型技术持续升级,面临持续创新压力
为“围剿”英伟达,国内厂商逐渐分化两条现实路径,一是以燧原、天数智芯等为代表的多数厂商,为避免和英伟达竞争,从对硬件、软件要求都不高的推理场景抓起。
另一条为摩尔线程、华为为代表的少数厂商,选择从千卡向万卡进发,着重训练场景,直接硬刚英伟达。
如摩尔线程的夸娥(KUAE)智算集群解决方案基于大模型智算加速卡MTT S4000,从千卡可扩展至万卡集群,以打造大模型和通用人工智能的先进算力基础设施。
摩尔线程创始人兼CEO张建中表示,夸娥万卡智算集群作为摩尔线程全栈AI战略的一块重要拼图,可为各行各业数智化转型提供澎湃算力。
厂商的理想或许很美好,但现实却是国产AI芯片落地过程难免出现各种问题。华为推出的升腾Ascend系列AI芯片客户包括讯飞、百度、腾讯等互联网大厂。但援引英国《金融时报》报道,在AI模型训练方面,Ascend和英伟达芯片仍存在差距,先后出现稳定性问题、芯片之间连接问题、华为CANN平台错误频传问题等等。百度使用华为芯片时常出现崩溃,进而影响AI项目的开发工作。
为解决问题,华为直接派出工程师到现场处理客户问题,百度、科大讯飞和腾讯均有华为团队支持。华为Ascend系列芯片在给摩尔线程敲响警钟的同时,相较于家大业大的华为来说,摩尔线程在资金、人员配置等方面稍有不足。若采取和华为常用的“堆人头”定制化服务方式,对其综合成本、现金流和盈利也提出高挑战。
除上述问题外,当前全球GPU厂商所面临的难题为AI大模型技术迭代速度过快和芯片长开发周期的矛盾,这对摩尔线程的持续创新能力、市场洞察能力均提出极高要求。
今年以来半导体产业重点关注高带宽存储器以及高速传输技术两大方向,这点不管从三星、SK海力士、美光快速调配产能,加速量产HBM来满足市场需求,还是运算芯片大厂陆续投入通信与传输技术开发,如英伟达的NVLink、英特尔主导的UALink,博通及Marvell都全力投入各层次高速传输技术开发,联发科和神盾集团通过SerDes和UCIE相关IP技术切入市场均能侧面证实。
但GPU中行业IP核占用的面积超过80%。但IP的研发并不轻松,GPU IP自研需要36—48个月以及200个工程师。采用外购IP虽能将开发周期缩短12—18个月。且高端芯片前端和后续设计1—3年,流片环节需3—6个月。若流片失败,只能继续上演该过程。且即使流片成功,还需经过3—12个月产品测试优化,才能开启量产。
这就意味着GPU厂商提出的AI芯片设计理念在当时或许很新颖,但若是被制成成品时,很有可能无法跟上市场需求和业界技术进展,最终被市场所淘汰。
换言之,AI大模型时代下GPU厂商面临压力远比此前更大,想要生存更加不易。张建中也曾指出,摩尔线程目标为至少先存活10年。
03.国产GPU洗牌加剧,摩尔线程迎大考
不仅仅是摩尔线程想要“活下来”,国内很多投资人也不断告诉自己的被投项目需要“先活下来”。
近两年,国内GPU厂商从一度当红的芯片领域,但在地缘政治带来的不确定以及经营管理团队融资欠缺等多因素共同影响下,行业急转直下。
烧光融资的GPU厂商,或裁员或解散。进而到2024年,这种情况不仅未能迎来改善,反而仍在继续恶化,国产GPU行业正迎来洗牌整合期。虽说燧原6年完成10次融资,累计融资金额高达70亿元,目前正启动A股IPO进程。但并非所有GPU厂商都有燧原这么“幸运”累计获约25亿元融资,估值约150亿元,且为重庆当地AI独角兽的象帝先因和资本对赌失败,反遭投资者反扑。业务关停、大规模裁员、创始人从“吸金人”变成失信人。
 图源:象帝先官方
图源:象帝先官方
南京砺算子公司砺算上海,近期虽获得东芯与其他投资者投资2亿元、1.28亿元,暂时解除资金链断裂危机,但GPU的重资金属性意味其后续可能还需寻求大量外部资金续命。大量GPU公司的倒闭让投资人血亏,对GPU项目愈发谨慎背景下。全球科技市场的持续生变,让该问题更加雪上加霜。
宏碁董事长暨执行长陈俊圣指出,全球科技产业正上演恐怖电影。厂商或建立算力中心或建立资料中心,虽说发展路径不同,但均需要服务器、存储器、海量数据。投入这么多成本,又要多少厂商挖到金矿?微软通过Copilot虽有所受益,但其又是否会愿意投入下去呢?或许当前厂商仍关注AI硬件、算力等等,但核心仍是商业模式得以延续。
陈俊圣的担忧正是当前全球科技产业的真实写照,这轮全球AI大模型浪潮,短期内除英伟达外,真正利润大幅度增长的厂商有限。在AI大模型上游,AI大模型的爆发让国产服务器一哥、号称算力龙头的浪潮信息2024年上半年业绩大增、转亏为盈,业绩创下历史新高。
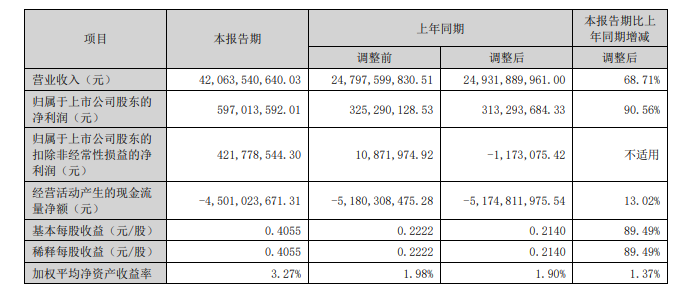 图源:浪潮信息财报
图源:浪潮信息财报
但浪潮信息业绩大幅度改善的背后,颇有以价换量意味。2024年上半年7.74%的毛利率创下浪潮信息近几年最低毛利率,浪潮信息方面称,毛利率下跌主要受客户结构、产品结构、原材料供应、市场竞争等多方面的综合影响。换言之,若后续GPU厂商竞争激烈,是否同样会采取以价换量策略呢?
 图源:浪潮信息财报
图源:浪潮信息财报
对大模型厂商来说,Open AI仍处在亏损中。援引The Informantion报道,Open AI的营收虽从2023年底的16亿美元快速上涨到今年上半年的34亿美元。但《纽约时报》预测,Open AI的技术投入或超过70亿美元,为其收入的2倍以上。目前Open AI正调整组织架构,募集新一轮资本。
但Open AI的34亿美元收入建立在周活跃用户2亿,每月收费20美元的基础。国内又有多少大模型厂商,能做到GPT的用户规模且让用户愿意持续付费呢?当大模型厂商长期处在亏损中,并不断调整算法模型降低对AI芯片的需求,GPU厂商又会面临何种问题呢?
此外,目前本土GPU芯片跟英伟达的产品相比,仍存在不小差距。从芯片设计上来看,跟英伟达的差距为12—18个月。在芯片制造制程上,英伟达已采用3纳米制程,国内目前止步于5-7纳米,这让本就处在融资难、退出难的资本市场不得不更加谨慎。
随着客户结构和AI大模型市场的改变,摩尔线程又要如何应对未来可能出现的资金流问题,持续补充业务所需大量资金呢?
或许摩尔线程所经历的这些问题,正是当前国内众多GPU厂商的现状。正如张建中所言,摩尔线程希望做的事情是解决最难做的事情,帮助国家、帮助行业解决缺少大算力的问题。
在国产替代这条路上,或许摩尔线程仍有诸多难题需要一一解决。但正是众多摩尔线程厂商的出现,国内和海外的差距才有望逐渐缩小,并可能实现反超。
1.TMT观察网遵循行业规范,任何转载的稿件都会明确标注作者和来源;
2.TMT观察网的原创文章,请转载时务必注明文章作者和"来源:TMT观察网",不尊重原创的行为TMT观察网或将追究责任;
3.作者投稿可能会经TMT观察网编辑修改或补充。
